
260MB

0.97MB

171MB
MoeTTS是一款语音合成软件,可以在软件上输入日语,让你选择模式大声朗读文字。适合需要制作演讲文档的朋友。我相信很多用户对语音合成都很了解,他们可以通过使用一些语音字符来大声读出他们的输入文本,从而获得一个音频文件。如果你不想自己录音或配音,可以让电脑软件为你朗读课文,从而完成配音。如果需要合成日语音频,可以通过这个MoeTTS软件合成语音。提供了软件Tacotron2模型和HifiGAN模型。可以将模型加载到软件中,输入文字内容进行合成,方便用户对动画内容进行配音。有需要就下载吧!
 软件功能
软件功能1.MoeTTS提供语音合成功能,让角色模型说话。
2,直接输入文字内容,选择型号,然后马上合成语音文件。
3.现在一些AI角色模型通过语音合成说话。
4.通过训练大量的语音数据,角色模型可以说任何话。
5.MoeTTS提供了大量的模型内容。将模型加载到软件中,输入日语,就可以合成语音内容。
6.可以在软件中加入Tacotron2模型和HifiGAN模型来合成新的语音。
7.支持多角色合成,支持单角色合成,轻松输出语音文件。
1.计算机AI角色可以通过合成语音说话,可以用于配音。
2.制作视频时,如果不喜欢自己说话,可以让AI角色说话。
3.可以通过合成语音自动朗读,可以输入任意文本内容大声朗读。
4.提供十多个角色,在VITS-多界面中可以添加多角色模型。
5.支持日文内容到g2p的转换,方便将转换后的文本添加到软件合成语音中。
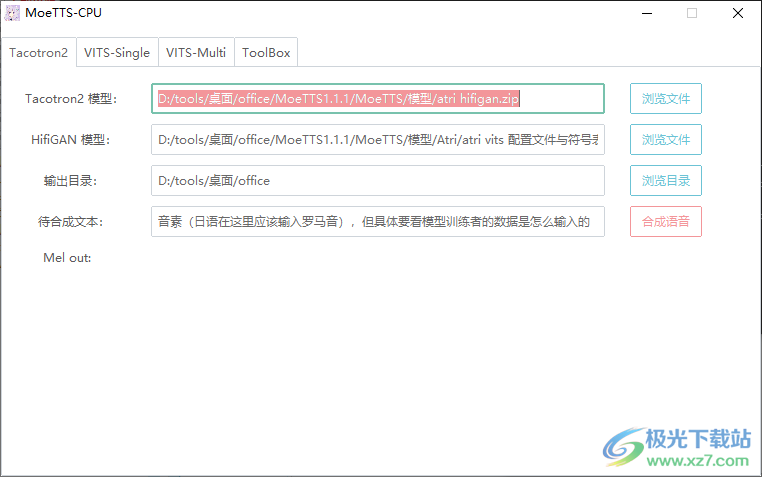
1.下载后打开moe_tts_cpu_with_tool.v1.1.1文件夹,找到moe_tts_cpu_with_tool.exe,直接启动。
 2.以下是模型的内容。可以加载软件提供的模型。
2.以下是模型的内容。可以加载软件提供的模型。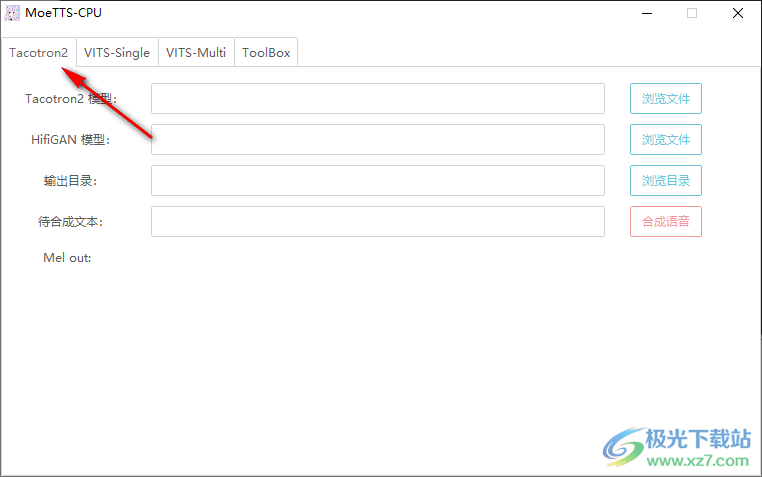 3.添加合成内容,并直接输入日文内容,通过罗马字符输入日文。
3.添加合成内容,并直接输入日文内容,通过罗马字符输入日文。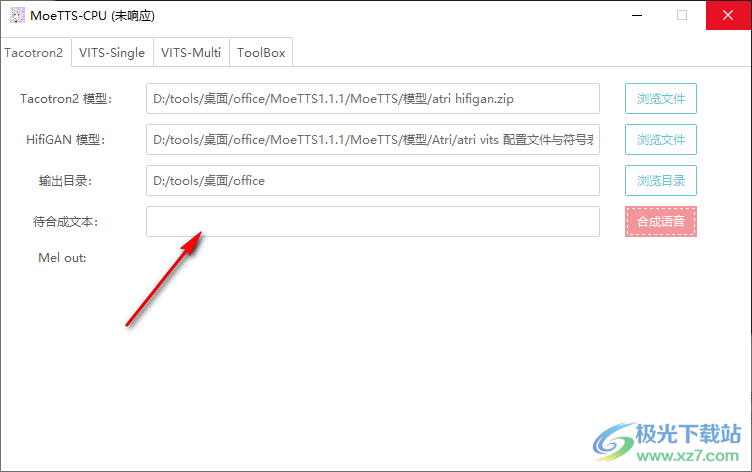 4.单模型界面,点击浏览文件找到模型内容,点击设置输出地址,设置文字立即合成语音。
4.单模型界面,点击浏览文件找到模型内容,点击设置输出地址,设置文字立即合成语音。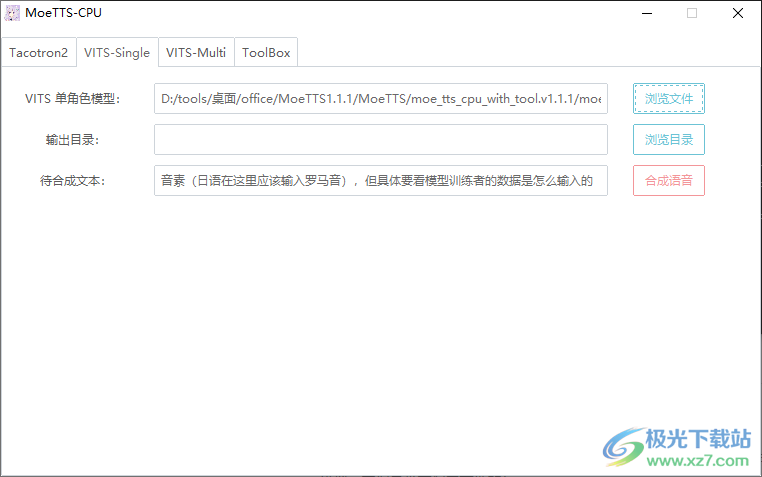 5.多角色模型生成界面。您可以设置帮助您朗读文本所需的角色ID。
5.多角色模型生成界面。您可以设置帮助您朗读文本所需的角色ID。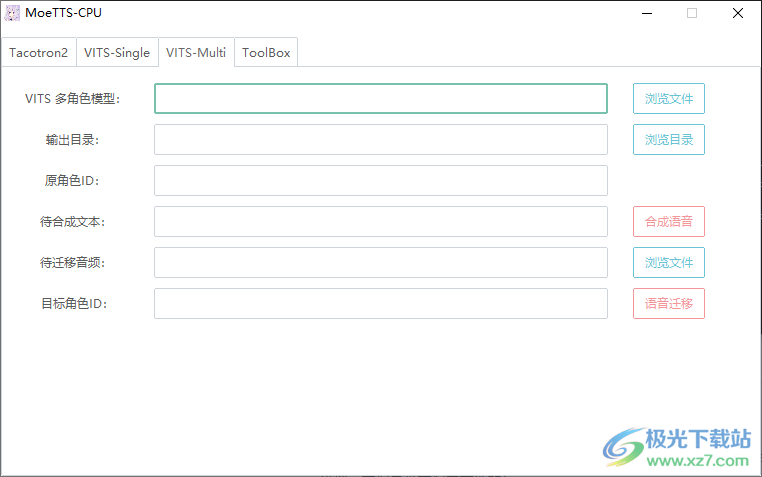 6.工具箱界面,输入日文文本,转换成g2p。可以选择常用转换,空间分段设置,分段+形状调整。
6.工具箱界面,输入日文文本,转换成g2p。可以选择常用转换,空间分段设置,分段+形状调整。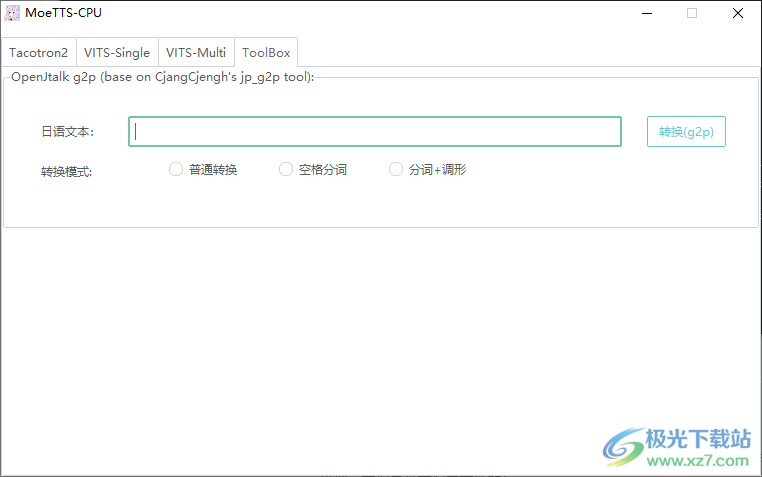 免费教程
免费教程可以查看视频教程内容。
型号目录格式
模型可以放在任何地方。如果模型带有配置文件,请将其重命名为config.json,并将其放在与TTS模型相同的目录中。(例如hifigan、vits型号,它们随配置文件一起提供)
VITS模型,请将config.json中的cleaners改为custom_cleaners。
文本输入格式
一般字符都是输入音位(这里日语应该是输入罗马字符),但是要看模型训练器的数据是怎么输入的。举个例子,我的ATRI模型(Tacotron2版本)是输入一个不带空格的罗马字,标点符号只支持逗号句号。
自定义清除程序和符号
您可以在与moetts.exe相同级别的目录中找到自定义文件夹,其中存储了两个模型的文本模块。
自定义Cleaners:只需找到cleaners.py,修改custom_cleaners函数(默认情况下,软件只会删除符号中没有的字符,不会对文本做进一步处理)
自定义符号:找到symbols.py并使用其中的符号作为您需要的符号。
注意:不同型号可能使用不同的清洁剂和符号训练。请根据需要进行修改,以确保模型的正常使用。
图形用户界面的使用
tacotron2
选择你的模型路径和输出目录,最后输入要合成的文本。点击合成语音,稍等片刻。软件会将音频输出到输出目录/outpus.wav。
注意事项:
第一次合成需要加载模型,耗时较长。如果再合成同一个模型,就不会再加载了,直接合成。
如果模型被切换,重组将被重新加载。
如果修改了清洁剂和符号,只有重新启动软件才会生效。
该软件是64位版本,不支持32位系统。
VITS特别说明
VITS-单和VITS-多分别是单角色模型和多角色模型。
VITS多声道中的原始字符ID是要合成的声音的字符ID,需要用数字填充。目标角色ID是要迁移的语音迁移功能的目标角色ID。
要迁移的音频需要22050的采样速率、16位和单声道。






























 皇家骑士团:重生它现在位于PS5/PS4/PC/NS上。
皇家骑士团:重生它现在位于PS5/PS4/PC/NS上。 蝙蝠侠配音演员凯文·康瑞去世,享年66岁。
蝙蝠侠配音演员凯文·康瑞去世,享年66岁。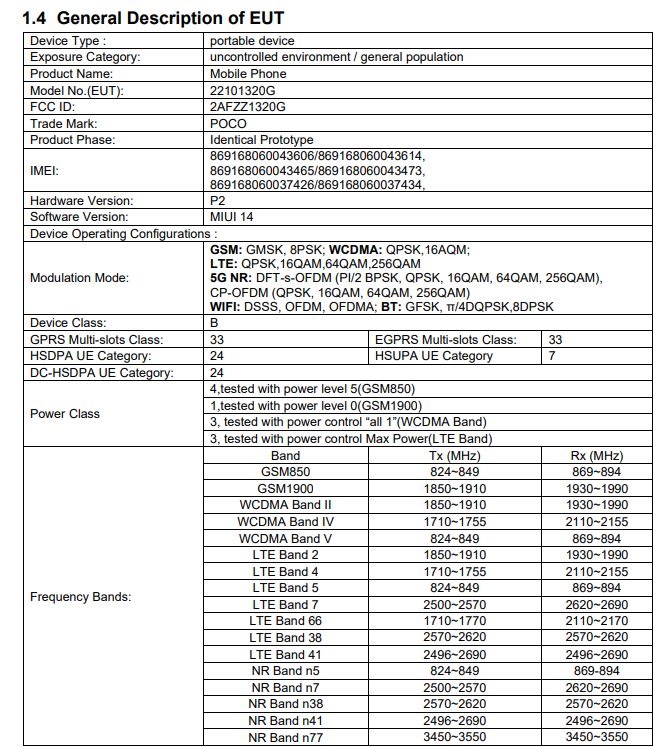 小米POCOX5首次曝光:开机是MIUI14
小米POCOX5首次曝光:开机是MIUI14 首款国产游戏显卡来摩尔线程MTTS80,售价2999元。
首款国产游戏显卡来摩尔线程MTTS80,售价2999元。 Twitter信任和安全部门主管离职,销售经理撤回辞呈
Twitter信任和安全部门主管离职,销售经理撤回辞呈 8家日本公司联合成立半导体公司Rapidus,制造高级芯片。
8家日本公司联合成立半导体公司Rapidus,制造高级芯片。 博德之门3将于2023年正式发售。更多信息将于12月发布。
博德之门3将于2023年正式发售。更多信息将于12月发布。 小米迄今为止最薄的笔记本,双十一就卖出去了!JD.COM销售额排名第一。
小米迄今为止最薄的笔记本,双十一就卖出去了!JD.COM销售额排名第一。






